Reward based ε decay
Background
In Reinforcement Learning(RL) the core problem is often phrased as that of an agent learning to interact with an environment. An agent’s behaviour in an environment is defined by its policy. We will be looking into a subset of such algorithms known as on-policy algorithms. Here the agent has only one single policy governing its movement in the environment. The agent uses the same policy to explore the environment and act in it.
Exploration VS Exploitation
At any given point an agent can act greedily based on the information that it has to maximize the total rewards that its expects to obtain. This is also known as exploitation.
Exploitation comes with a major drawback. The agent acts only on the basis of its knowledge of the environment, which may be incomplete. This is especially problematic if an agent has just began its interaction with the environment. Acting only greedily based on it’s limited knowledge of the environment is makes it very unlikely for agent to learn the optimal behaviour in the environment.
How will one know what lies behind door number 2 if one is satisfied with the reward it gets from door number 1?
This is where exploration comes in. When a agent explores it does not necessarily act to the best of its knowledge, instead it explores different options available, dictated by some exploration strategy.
What good is trying to know about what’s behind every door if one never makes use of that information?
Epsilon Greedy
Now that we are aware of the need to balance exploration and exploitation, we are ready to talk about Epsilon Greedy. It is one of the most popular strategies to balance exploration and exploitation. Here is how it goes.
ε is assigned a real number between 0 and 1.
With probability ε the agent chooses a random action.
With probability 1-ε the agent acts greedily.
Here we have established a strategy to exploit and explore based on a variable. A value of ε closer to 1 will result in greater exploration. Conversely, a value closer to 0 will result greater exploitation.
The Decay
It is also important to note that exploration is more important when the agent does not have enough information about the environment its interacting with. Once an agent does have the information it needs to interact optimally with the environment, allowing it to exploit its knowledge makes more sense.
We can thus see that the value of ε should decay across the life of an agent to have it learn and act optimally eventually.
A common way to obtain this by multiplying Epsilon by a real value less than 1 every episode. For example, ε = ε*0.9. This would result in a gradual decay in epsilon with more and more episodes.
The Reward Based Decay
An alternate approach to epsilon decay that I found useful in certain problems, is using the reward to decide the decay. Only when an agent has crossed some reward threshold, the value of ε is reduced. Instead of assuming that the agent is learning more every episode, we wait for proof of agent’s learning before reducing the epsilon value. Thus we set higher targets for agent every time ε is lowered, and wait for agent to reach the newer target before repeating the same steps again.
Code
Let us now take a look at how it would look in code.
General pseudocode
if EPSILON > MINIMUM_EPSILON and LAST_REWARD >= REWARD_THRESHOLD:
EPSILON = DECAY_EPSILON(EPSILON)
REWARD_THRESHOLD = INCREMENT_REWARD(REWARD_THRESHOLD)
The two function calls in the above algorithm for epsilon decay and increment can be adjusted to user needs. The decay and increment could be additive or multiplicative or something else entirely, depending on the use case. This code snippet is what would replace the simple ε=ε*decay_rate used in exponential decay. The key idea presented here is that only when the agent meets or surpasses the reward threshold, is the epsilon decayed.
Decay plan for OpenAI’s CartPole-v0
The problem is considered solved when the agent gets an average reward of 195 over 100 consecutive trials. The maximum attainable score from any episode is 200. A standard start and end value for ε could be 1 and 0 respectively, where we start with maximum possible exploitation and end with maximum possible exploitation. Since all the rewards we obtain are whole numbers, we can at least increment target reward thresholds by 1 to make newer thresholds more challenging than the last one. The final parameter that remains to be decided is the number of steps to take form maximum exploration to maximum exploitation. Since the problem statement has a well defined goal of reaching 195, it is possible to use that to decide the steps. We calculate the steps by assuming that the agent should reach the final goal threshold with exploitation alone.
EPSILON = 1.0
MINIMUM_EPSILON = 0.0
REWARD_TARGET = 195
STEPS_TO_TAKE = REWARD_TARGET
REWARD_INCREMENT = 1
REWARD_THRESHOLD = 0
EPSILON_DELTA = (EPSILON - MINIMUM_EPSILON)/STEPS_TO_TAKE
When time comes to decay ε the values are conditionally adjusted.
if EPSILON > MINIMUM_EPSILON and LAST_REWARD >= REWARD_THRESHOLD:
EPSILON = EPSILON - EPSILON_DELTA
REWARD_THRESHOLD = REWARD_THRESHOLD + REWARD_INCREMENT
Results
The biggest advantage observed here is controlled epsilon decay across the life of an agent irrespective of how fast or slow the agent learns. Thus removing the reliance of decay on number of episodes. The results produced are more stable results and easier to replicate. Using RBED instead of exponential decay in the Neural Episodic Controller solution by Karpathy, yields over 500% improvement in agent’s ability to solve the environment within 500 episodes.
Results of above code snippet in OpenAI’s CartPole-v0 can be seen the graphs below.
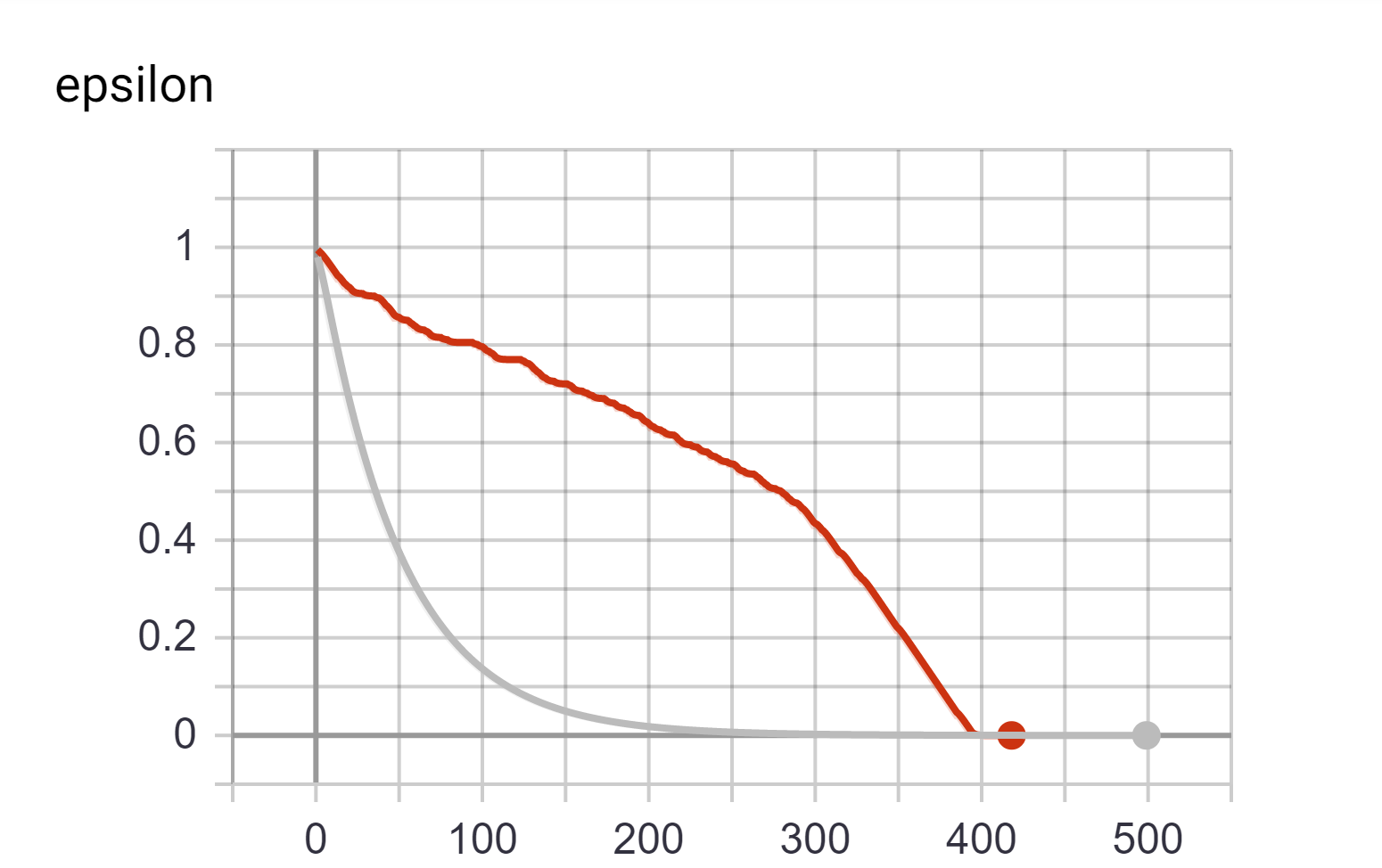
Comparison of how ε decays across episodes. Red line represents Reward based decay and grey line represents exponential decay.
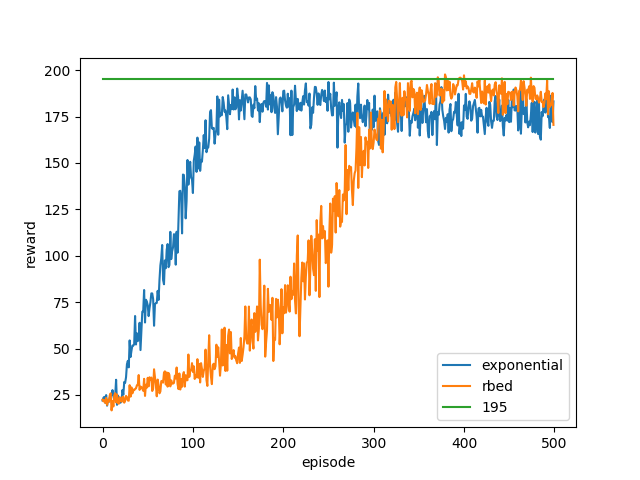
Comparison of reward obtained by the agent at every given episode, averaged across 20 runs. Rbed makes it more likely for the agent to cross the threshold of 195. The graph also depicts that while exponential ‘peaks’ earlier when compared to rbed, it fails to reach a value as high.
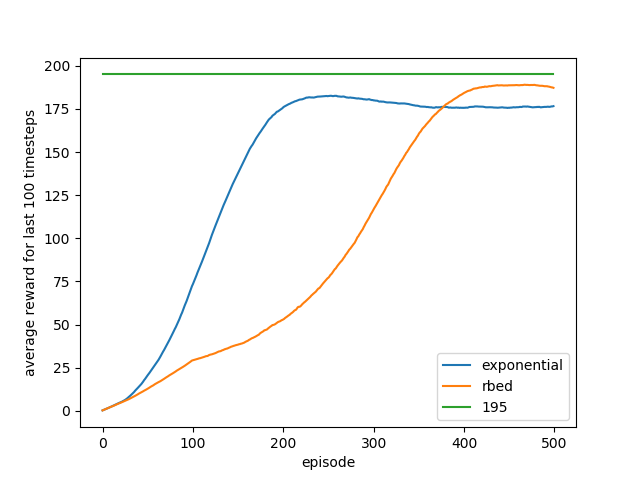
Comparison of average reward obtained across last 100 episodes, averaged across 20 runs. This is the metric used to determine the solution of the environment. The long term trend agrees with the experimental results that rbed is more successful in finding a solution.
Reward based ε decay strategy also outperforms exponential decay strategy when used with DQNs on the same problem, with the added benefit of easier hyperparameter tuning. Not only does it solve the environment quicker, it does so more consistently.
Intuition
Another way to interpret this decay strategy is based on responsibility. An agent is granted greater responsibility to act as it accomplishes greater rewards. Agent failing to meet the targets will be compelled to explore more until it does meet the targets.
Conclusion
While this decay strategy might not be suitable for a lot of environments and problem statements, it does bring few good to have benefits in cases where it does. It removes a lot of uncertainty around the exploratory nature of an agent. Should the agent be exploring more? Has the agent explored enough? A reward based approach yields much easily understandable parameters which can be tweaked to get desired results.
The parameters here are more related to the environment and task than they are to an agent. Agents, irrespective of their learning capabilities will get similar exploratory freedom at any given stage based on their accomplishments.